- Project NameWeird Music Searcher
- Project Type & Time2020, Course Design
- My dutyComplete independently
- Technology InvolvedWeb crawler, Search Engine, Front-end&Back-end development
- Framework AdoptedWebMagic,Lucene,SpringBoot,Mybatis,MySQL
- Run it onlinesse.hita.store
Weird Music Searcher
The course design of Information Retrieval in my sephomore year, but in order to learn the front and back ends I over-completed.
System Design
This system can run in Windows and Linux environments (the deployment environment is Aliyun Linux), based on the Springboot framework and developed in java language. The back-end program includes three parts: crawler, index, and search. Among them, the open-source framework webmagic is used for web-crawling, the jsoup tool is used for website analysis and information extraction, and the information is structured and connected to the MySQL database for storage using mybatis. Indexing and retrieval are done by the Lucene framework, in which ansj is used for Chinese word segmentation during the establishment of retrieval and search. The front end includes a search page and a result list page, which are connected using the thymeleaf framework.
Crawlers and indexes are triggered by background control. Every time the index needs to be rebuilt, the MySQL temporary storage table is cleared, and page crawling is performed asynchronously. When the crawled pages reach a certain size (such as 200,000), the crawling is stopped and a new one is created. The document index replaces the original index library. Except for the short time required to replace the index library, the front-end page and retrieval program are in normal working condition at any other time. After the user enters the search sentence, the back-end fast word segmentation, index query, document scoring, and sorting can be quickly obtained Relevant document search results.
Module Design
Crawler
A crawler program is designed based on the webmagic framework to crawl the music homepage of Douban Music (url format is https://music.douban.com/subject/music_id). Use random UserAgents and constructed Cookies, an IP pool with a valid time of 5 minutes and a size of 10 to prevent Douban from blocking the ip, and open 64 threads for crawling at the same time. For each song or album page, extract its title, artist and other release information, introduction and track list as basic information, save the song image url for front-end display of search results, and the most important thing is the popular reviews and music reviews of the page List extraction and integration. After the information is extracted, it is saved in the mysql database in the form of the following figure:
The initial page queue contains representative works of Chinese, European and American popular male and female singers and groups, so as to ensure that crawlers can get more "mainstream" pages. It is observed that when the number of pages obtained by the crawler exceeds 200,000, the "number of ratings" field has all tended to -1 (indicating that the song is unpopular), so 200,000 pieces of data can meet the query requirements of mainstream music.
Indexing
Use the indexing tool provided by Lucene to construct an index database based on the page information stored in mysql. In order to prevent a large number of repeated words in the official introduction from increasing the search ranking, the weights of this attribute are reduced accordign to their length when constructing the index. The "comments" and "reviews" contain the user’s evaluation information for the song, and the number and total length of the comments and music reviews can reflect the “popularity” of the music to a certain extent, that is, the importance, so the title and these two attributes adopt complete word segmentation, and consider word frequency, word position and offset index construction method.
Among them, the selection of word segmentation methods and word segmentation tools have a greater impact on the search results. I tried the word segmenter provided by Lucene, but I couldn’t get the desired result. After using the granular mode of IKAnalyzer, the effect has been improved. However, because the singers' names are frequently seen in the songs' information, and IKAnalyzer does not have the function of Chinese name recognition, so There appeared the lyrics "一杯敬明天" from the search for "萧敬腾(singer's name)", just because they both contains the character "敬". The reason is that IKAnalyzer could not recognize "萧敬腾" and cut out "敬". Therefore, I chose the Ansj word tokenizer that supports person name recognition and use the search word segmentation mode, and add a custom dictionary to specify the proper nouns in the music field as shown in the following figure:
This ensures that in the "music information search" scenario, words that are highly relevant to the music topic can be correctly cut out and indexed.
Searching & Ranking
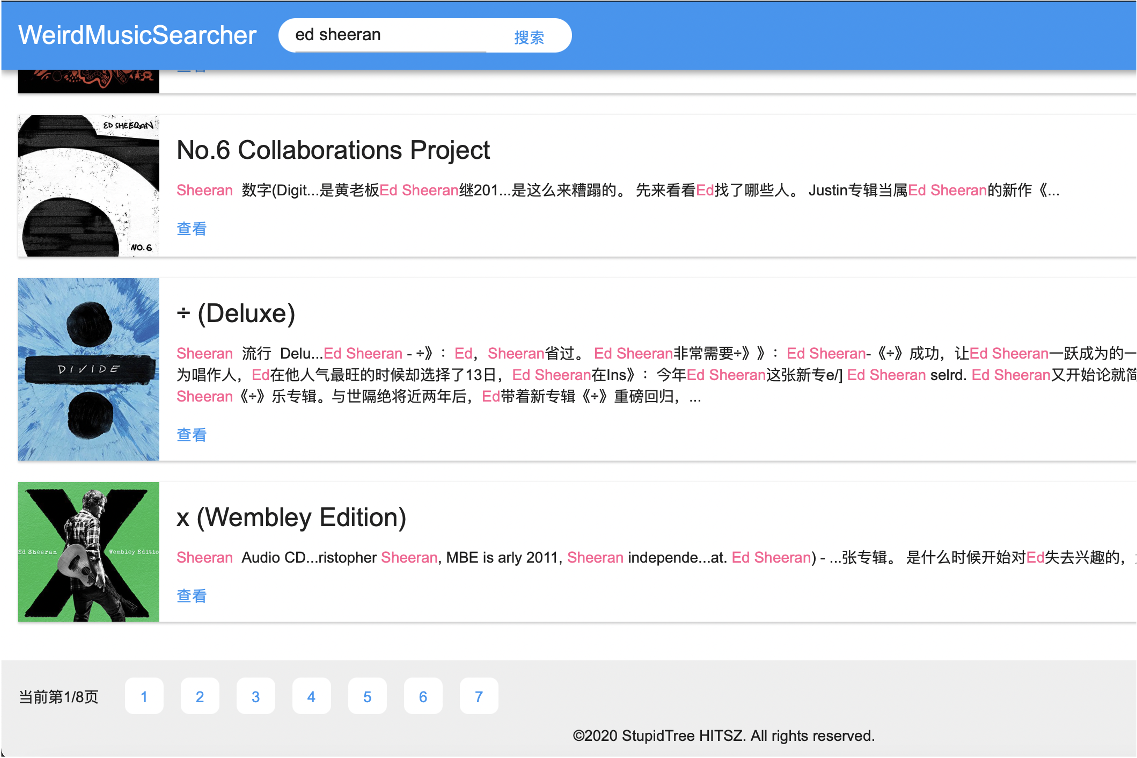
Using the multi-domain search method provided by Lucene, along with Ansj as the word segmentation tool, the system's seaching and ranking module are constructed. Among them, different domains (title, introduction, comment, etc.) are assigned with different search weights. Give title five times the weight of other domains, because music search must give priority to title; considering that the track list information may contain a lot of information that is repeated with the title (for example, the song name appears again in tracklist), which is not ideal. Therefore, the weight of the repertoire is reduced; music reviews, user reviews, and song descriptions are assigned medium weights, because these fields are likely to contain the surrounding information of the song, such as the singer’s nickname, the background of the singer, and so on. In order to optimize for the senario of music search, the terms of the search sentence need to be processed. For example, when no additional processing is performed on Term, the result of searching for "李荣浩's Song" is shown in the following figure:
It can be seen that due to the high number of occurrences of "歌曲song" in the second item, it has a higher score. Although it has nothing to do with 李荣浩, it still ranks ahead of "李白", which is 李荣浩's most famous song. In the searching senario of Douban Music, words such as "歌曲song" are actually irrelevant. Users are more concerned about "李荣浩", and the particle "的" is also irrelevant. Therefore, additional processing must be performed on Term: with the help of ansj's part-of-speech tagging function, the retrieval weights of particles, prepositions, interjections, and short-length terms are reduced, so as to avoid those that contain a large number of Query "unimportant" terms. Related documents are ranked high; for terms that are highly relevant to the music search engine, such as "songs" and "music", the weights are also greatly reduced, because the purpose of using this engine is to search for songs. Words such as "song" are equivalent to nonsense; for nouns, especially names (because the user has a high probability of entering the singer's name), they are given higher weight, because these words are often the core information retrieved by users. After optimization, search for "Li Ronghao's Songs" again. The same position on the first page of the results is all Li Ronghao's songs. This is an ideal result, as shown in the following figure:
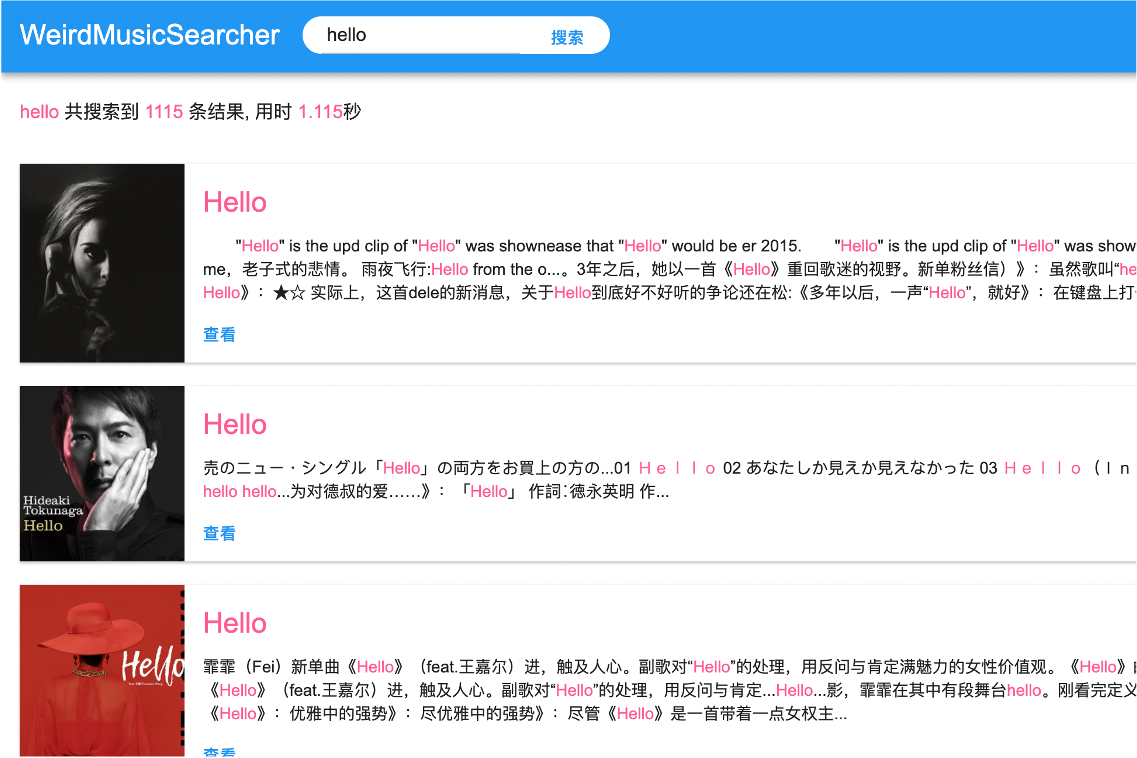
In addition to extra processing based on word lines, other attributes of the retrieved songs must also be considered for ranking the results. The default return result of Lucene search is a list of documents sorted by relevance score, and this system performs sorting optimization on this basis. Consider the number of people rated by Douban to appropriately increase the score of "famous songs" and reduce the score of results that contain a large number of repeated frequently used words. For example, when searching for "Hello", multiple results titled "Hello" can be matched. The top three rankings are shown in the following figure (for clarity, the ranking score is displayed next to the title):
The names of the three songs are "Hello", and the scores are similar. However, it is observed that the number of ratings for the first and second songs is less than 300, while the number of ratings for Adele's Hello is more than 6,000. It is the result that most users expect that Adele's Hello is ranked first. Therefore, a $\sigma$ is added to the search ranking score $s$, and $s'=s+\sigma$ is used instead as the result ranking basis. The design calculation formula is as follows:
Consider a set of songs of size n, the similarity between each song and the retrieval sentence is $s_i$, and the number of scorers is $v_i$, then $\sigma_i$ can be calculated by the following formula:
$$\sigma_i = \lambda \frac{s_i}{\Sigma^n_{k=1}s_k} \frac{v_i}{\Sigma^n_{j=1}v_j}$$
Among them, $\lambda$ is a constant. This method of calculation can ensure that among the search results, the more "hot" music with similar relevance can be ranked first, and the less relevant music will not rise to the top because of its popularity. When taking $\lambda=2.4$, the search results of "Hello" are sorted and scored as follows:
Evaluation
Using 14 music-related searches of different lengths and random fields, the precision calculated according to the first ten results given by the search engine is shown in the following table. The average accuracy of the 14 query macros with precision can be calculated to be 0.954. If the precision is calculated based on the first five results, it can reach 0.988.
Evaluate the search time of the above 14 searches. The test environment is Aliyun lightweight application server, the system is Aliyun Linux 2.19.03, single-core CPU, 5Mbps peak bandwidth, 2G memory. The timing starts when the retrieval request is received, and the result list generation ends. Perform 5 retrievals on each of the above 14 queries, and take the average of the 70 retrieval times as the evaluation response time. The results are shown in the following table:
Calculated by macro average, the average response time is 0.070 seconds.
Main difficulties
The primary difficulty of the project lies in the crawler. Due to Douban's anti-crawler mechanism, high-speed access to more than 100 Douban music websites in a short period of time will result in IPs being blocked. Therefore, a dynamic ip pool is used, and 10 temporary IPs are pulled from a third-party ip provider every 5 minutes. During this period, the crawler uses these IPs as agents until the end of 5 minutes or all ips in the pool are blocked. In this way, up to 320,000 Douban music pages were crawled at one time, all of which were stored in the mysql database.